The Biodiversity Data Puzzle
The WWF-SIGHT team recently authored a paper, ‘The Biodiversity Data Puzzle’ in collaboration with Maxar and including input from OS-Climate, Carnegie Mellon University, Google, and others.
Please read the report in full here: ‘The Biodiversity Data Puzzle’
The report looks at how, via geospatial-driven approaches, we might produce improved insights into the ‘ecosystem and biodiversity’ impacts of any given company. Essentially showing throughout that location is a useful tool. Once available, it can be used to circle around an asset, using multiple data techniques to triangulate impact, dependencies, or other aspects of interest.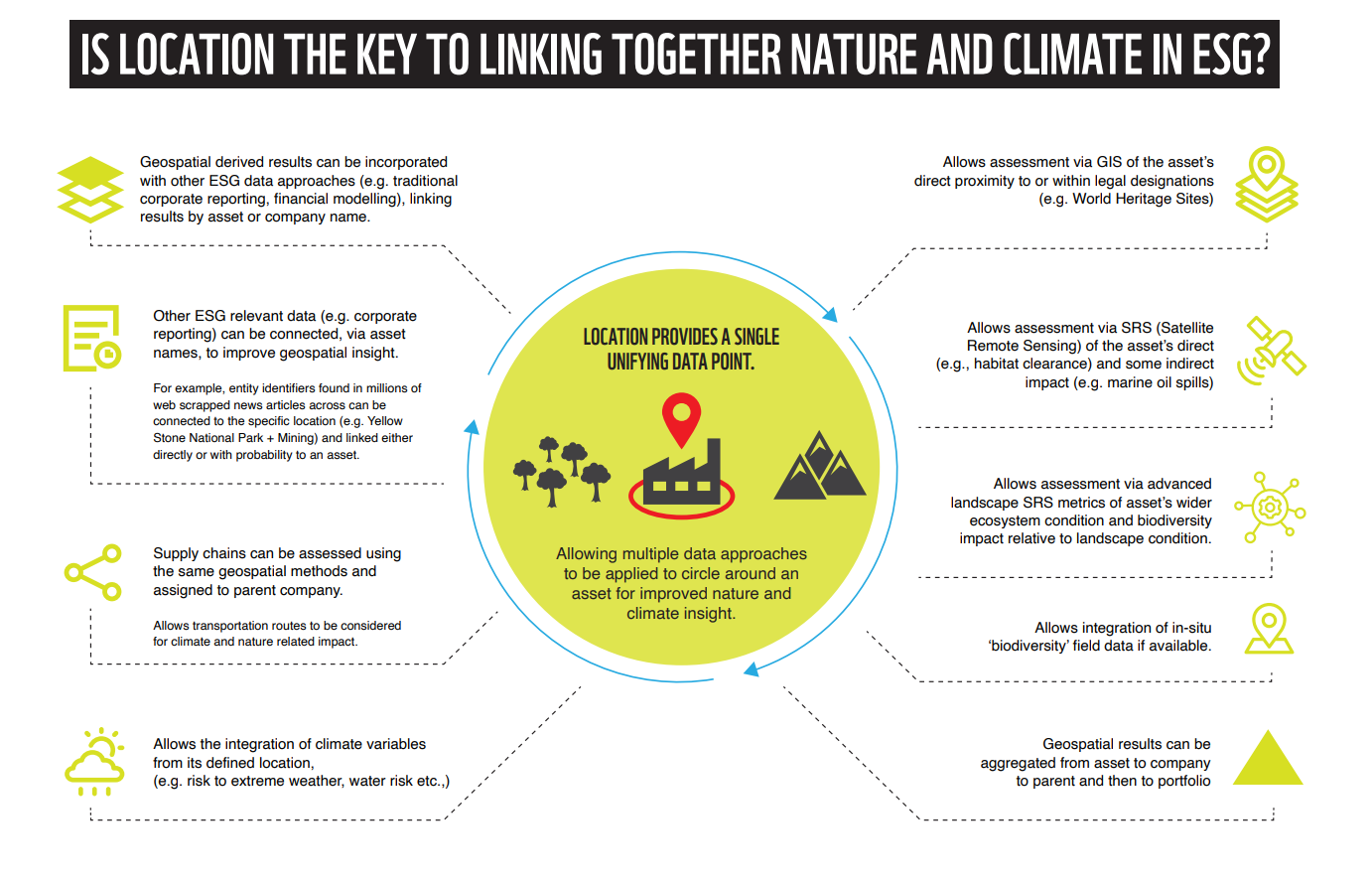 The report makes several conceptual contributions and, recognizing that data and models will evolve, outlines various data-agnostic concepts for discussion;
The report makes several conceptual contributions and, recognizing that data and models will evolve, outlines various data-agnostic concepts for discussion;
- To help remove the complexities around ‘causation’ (e.g. proving that a specific commercial asset caused a particular environmental impact), we propose the use of fixed area delineations. Specifically, defining the values within the internal property of any given asset (I); the bordering area near to the asset, based either on a ratio or fixed distance/s (B); within the landscape (L) (e.g. within the water basin); and globally (G). The IBLG model. Importantly, we propose methods for developing landscape condition metrics (L) to adjust the impact of values reported within IB values to the wider landscape situation.
- The report goes through in detail exploring concepts such as how we might define historic baselines, simplify ‘impact’ into direct and indirect within the IBLG spheres, aggregating supply chains (including transportation values), quantify impacts using peer-to-peer comparison, the inclusion of additional data sources (data triangulation). Raising the topics for wider discussion.
- Importantly while geospatial ESG methods have much to offer, particularly around the topic of ‘biodiversity’, the field is unlikely to scale organically scale without targeted intervention. Where without developing the necessary supporting public good data infrastructure to allow the flow and integration of data (in particular asset and supply chain data) across a diverse range of stakeholders the field and other related fields are likely to remain constrained. To overcome the current issues in a feasible manner, we propose the development of an international ‘centre’ to oversee the creation and maintenance of a public goods data commons, best practice, benchmarking, etc., to enable the flow and integration of data across the diverse range of stakeholders from satellite to spreadsheet (See diagram below)
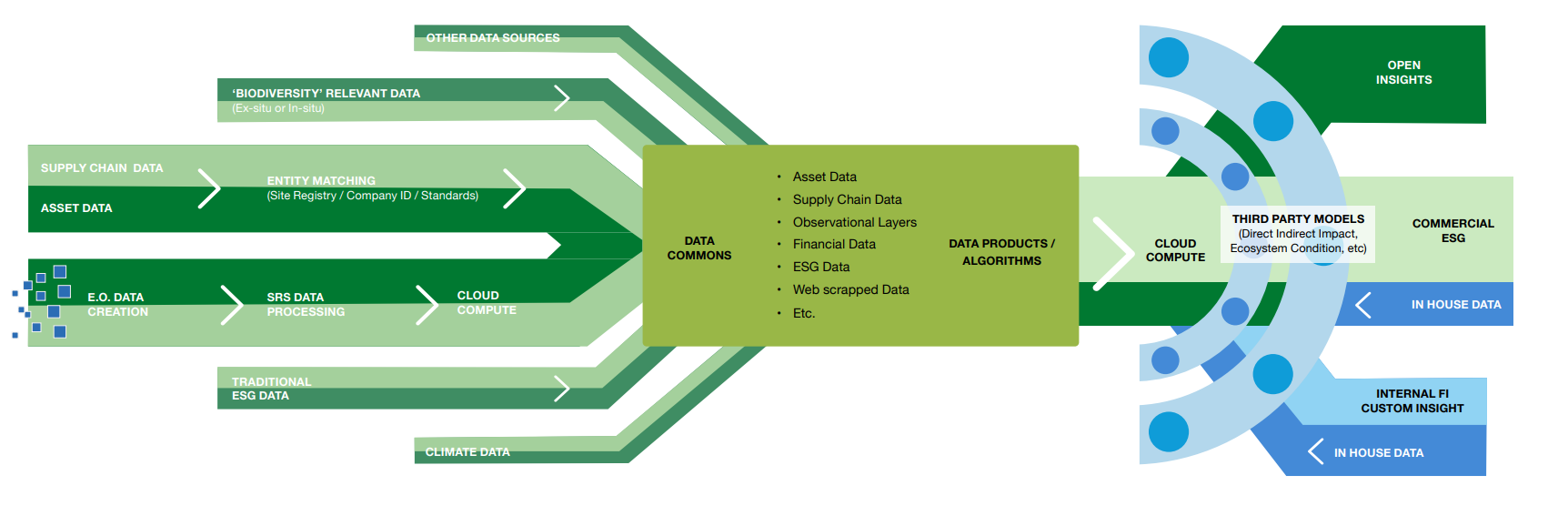
Many actors over the past few decades have made, and continue to make, significant progress in this space. Recognizing this we offer the concepts in the paper for discussion. It is now a rapidly developing field and is very exciting to watch develop as it has such huge potential for providing transparency and accountability.
A huge thank you to Maxar – and to everyone involved.
Report Links:
Please read the report in full here: ‘The Biodiversity Data Puzzle’